Интересную новость мы обнаружили вот тут. Оказывается утилита esxtop может работать в режиме повтора для визуализации данных о производительности, собранных в определенный период времени (многие администраторы знают это, но далеко не все). Это позволит вам собрать данные о производительности хоста, например, ночью, а в течение рабочего дня проанализировать аномальное поведение виртуальной инфраструктуры VMware vSphere. Называется этот режим replay mode.
Для начала запустите следующую команду для сбора данных на хосте VMware ESXi:
Мы часто пишем о том, что снапшоты в VMware vSphere - это плохо (за исключением случаев, когда они используются для горячего резервного копирования виртуальных машин и временного сохранения конфигурации ВМ перед обновлением).
Однако их использование в крупных инфраструктурах неизбежно. Рано или поздно возникает необходимость удаления/консолидации снапшотов виртуальной машины (кнопка Delete All в Snapshot Manager), а процесс этот достаточно длительный и требовательный к производительности хранилищ, поэтому неплохо бы заранее знать, сколько он займет.
Напомним, что инициирование удаления снапшотов в vSphere Client через функцию Delete All приводит к их удалению из GUI сразу же, но на хранилище процесс идет долгое время. Но если в процесс удаления возникнет ошибка, то файлы снапшотов могут остаться на хранилище. Тогда нужно воспользоваться функцией консолидации снапшотов (пункт контекстного меню Consolidate):
О процессе консолидации снапшотов мы также писали вот тут. Удаление снапшотов (как по кнопке Delete All, так и через функцию Consolidate) называется консолидацией.
Сначала посмотрим, какие факторы влияют на время процесса консолидации снапшотов виртуальной машины:
Размер дельта-дисков - самый важный параметр, это очевидно. Чем больше данных в дельта-диске, тем дольше их нужно применять к основному (базовому) диску.
Количество снапшотов (число дельта-файлов) и их размеры. Чем больше снапшотов, тем больше метаданных для анализа перед консолидацией. Кроме того, при нескольких снапшотах консолидация происходит в несколько этапов.
Производительность подсистемы хранения, включая FC-фабрику, Storage Processor'ы хранилищ, LUN'ы (число дисков в группе, тип RAID и многое другое).
Тип данных в файлах снапшотов (нули или случайные данные).
Нагрузка на хост-сервер ESXi при снятии снапшота.
Нагрузка виртуальной машины на подсистему хранения в процессе консолидации. Например, почтовый сервер, работающий на полную мощность, может очень долго находится в процессе консолидации снапшотов.
Тут надо отметить, что процесс консолидации - это очень требовательный к подсистеме ввода-вывода процесс, поэтому не рекомендуется делать это в рабочие часы, когда производственные виртуальные машины нагружены.
Итак, как можно оценивать производительность процесса консолидации снапшотов:
Смотрим на производительность ввода-вывода хранилища, где находится ВМ со снапшотами.
Для реализации этого способа нужно, чтобы на хранилище осталась только одна тестовая виртуальная машина со снапшотами. С помощью vMotion/Storage vMotion остальные машины можно с него временно убрать.
1. Сначала смотрим размер файлов снапшотов через Datastore Browser или с помощью следующей команды:
ls -lh /vmfs/volumes/DATASTORE_NAME/VM_NAME | grep -E "delta|sparse"
2. Суммируем размер файлов снапшотов и записываем. Далее находим LUN, где размещена наша виртуальная машина, которую мы будем тестировать (подробнее об этом тут).
3. Запускаем команду мониторинга производительности:
# esxtop
4. Нажимаем клавишу <u> для переключения в представление производительности дисковых устройств. Для просмотра полного имени устройства нажмите Shift + L и введите 36.
5. Найдите устройство, на котором размещен датастор с виртуальной машиной и отслеживайте параметры в колонках MBREAD/s и MBWRTN/s в процессе консолидации снапшотов. Для того, чтобы нужное устройство было вверху экрана, можно отсортировать вывод по параметру MBREAD/s (нажмите клавишу R) or MBWRTN/s (нажмите T).
Таким образом, зная ваши параметры производительности чтения/записи, а также размер снапшотов и время консолидации тестового примера - вы сможете оценить время консолидации снапшотов для других виртуальных машин (правда, только примерно того же профиля нагрузки на дисковую подсистему).
Смотрим на производительность конкретного процесса консолидации снапшотов.
Это более тонкий процесс, который можно использовать для оценки времени снапшота путем мониторинга самого процесса vmx, реализующего операции со снапшотом в памяти сервера.
1. Запускаем команду мониторинга производительности:
# esxtop
2. Нажимаем Shift + V, чтобы увидеть только запущенные виртуальные машины.
3. Находим ВМ, на которой идет консолидация.
4. Нажимаем клавишу <e> для раскрытия списка.
5. Вводим Group World ID (это значение в колонке GID).
6. Запоминаем World ID (для ESXi 5.x процесс называется vmx-SnapshotVMX, для ранних версий SnapshotVMXCombiner).
7. Нажимаем <u> для отображения статистики дискового устройства.
8. Нажимаем <e>, чтобы раскрыть список и ввести устройство, на которое пишет процесс консолидации VMX. Что-то вроде naa.xxx.
9. Смотрим за процессом по World ID из пункта 6. Можно сортировать вывод по параметрам MBREAD/s (клавиша R) или MBWRTN/s (клавиша T).
10. Отслеживаем среднее значение в колонке MBWRTN/s.
Это более точный метод оценки и его можно использовать даже при незначительной нагрузке на хранилище от других виртуальных машин.
Те, из вас, кто пользуется веб-средством vSphere Web Client для управления виртуальной инфраструктурой VMware vSphere, знают, что при логине в окно клиента в самом низу предлагают скачать Client Integration Plugin (CIP):
CIP - это пакет средств от VMware, представляющий собой набор полезных утилит для некоторых административных операций в виртуальной инфраструктуре. Утилиты доступны как для Microsoft Windows, так и для Apple Mac OS X (а скоро будет и поддержка Linux).
Посмотрим на состав этого набора:
ovftool - это отдельная утилита CLI, которую можно использовать для импорта и экспорта виртуальных модулей (Virtual Appliances) в форматах OVF и OVA.
Windows Authentication - позволяет использовать аутентификацию SSPI Windows при логине через vSphere Web Client.
Remote Devices - возможность подключить клиентские устройства (CD-ROM, Floppy, USB и прочие) к виртуальной машине.
File Upload/Download - это вынесенный в отдельную утилиту Datastore browser для загрузки файлов на виртуальные хранилища.
Content Library - операции импорта и экспорта для компонента Content Library.
Client Side Logging/Config - позволяет записывать логи на стороне клиента, а также реализует настройки логирования vSphere Web Client.
Процедура развертывания vSphere Client Integration Plugin выглядит примерно так (видео от версии vSphere 5.5):
Ранее CIP как браузерный плагин использовал модель Netscape Plugin Application Programming Interface (NPAPI), но поскольку в Google Chrome последних версий и прочих браузерах поддержка этой устаревшей модели была окончена, то теперь используется обновленная модель отображения, которая реализована, начиная с Sphere 5.5 Update 3a и vSphere 6.0 Update 1 (поэтому лучше CIP использовать с платформами этих версий или выше).
Более подробно об утилитах CIP рассказано вот тут.
Странные вещи происходят в последнее время с VMware. Сначала в технологии Changed Block Tracking (CBT) платформы VMware vSphere 6 был найдет серьезный баг, заключавшийся в том, что операции ввода-вывода, сделанные во время консолидации снапшота ВМ в процессе снятия резервной копии, могли быть потеряны. Из-за этого пользователи переполошились не на шутку, ведь бэкапы, а это критически важная составляющая инфраструктуры, могли оказаться невосстановимыми.
Недавно этот баг был пофикшен в обновлении ESXi600-201511401-BG, и вроде бы все стало окей. Но нет - оказалось, что накатить обновление на ваши серверы VMware ESXi недостаточно, о чем своевременно сообщила компания Veeam (официальная KB находится вот тут). Нужно еще и сделать операцию "CBT reset", то есть реинициализировать Changed Block Tracking для виртуальных машин.
Все дело в том, что уже созданные файлы CBT map могут содержать невалидные данные, касательно изменившихся блоков, а ведь они могли быть созданы еще до накатывания патча от VMware. Таким образом, простое обновление ESXi не убирает потенциальную проблему - старые файлы *-ctk.vmdk могут, по-прежнему, быть источником проблем. Удивительно, как такая могучая компания как VMware просто взяла и прошляпила этот момент.
Итак, как нужно делать CBT reset для виртуальной машины описано вот тут у Veeam. Приведем этот процесс вкратце:
1. Открываем настройки виртуальной машины (да-да, для каждой ВМ придется это делать) и идем в Configuration Parameters:
2. Там устанавливаем значение параметра:
ctkEnabled = false
3. Далее устанавливаем
scsi0:x.ctkEnabled также в значение false:
4. Открываем папку с виртуальной машиной через Datastore Browser и удаляем все файлы *-ctk.vmdk (это и есть CBT map файлы):
5. Включаем виртуальную машину и заново запускаем задачу резервного копирования Veeam Backup and Replication.
Для тех, кто умеет пользоваться интерфейсом PowerCLI есть бонус - компания Veeam сделала PowerShell-скрипт, который автоматизирует эту операцию. Он позволяет переинициализировать CBT для указанных пользователем виртуальных машин. Виртуальные машины со снапшотом, а также выключенные ВМ будут проигнорированы. Также надо отметить, что при выполнении сценария создается снапшот машины, а потом удаляется, что может вызвать временное "подвисание" машины и ее недоступность в течение некоторого времени, поэтому лучше выполнять этот скрипт ночью или в нерабочие часы.
Некоторое время назад мы писали об очень серьезном баге в технологии Changed Block Tracking, обеспечивающей работу инкрементального резервного копирования виртуальных машин VMware vSphere 6. Баг заключался в том, что операции ввода-вывода, сделанные во время консолидации снапшота ВМ в процессе снятия резервной копии, могли быть потеряны. Для первого бэкапа в этом нет ничего страшного, а вот вызываемая во второй раз функция QueryDiskChangedAreas технологии CBT не учитывала потерянные операции ввода-вывода, а соответственно при восстановлении из резервной копии такой бэкап был неконсистентным.
Мы писали про временное решение, заключающееся в отключении технологии CBT при снятии резервных копий продуктом Veeam Backup and Replication, но оно, конечно же, было неприемлемым, так как скорость бэкапов снижалась в разы, расширяя окно резервного копирования до неприличных значений.
И вот, наконец, вышло исправление этого бага, описанное в KB 2137545. Это патч для сервера VMware ESXi, который распространяется в виде стандартного VIB-пакета в сжатом zip-архиве.
Чтобы скачать патч, идите по этой ссылке, выберите продукт "ESXi Embedded and Installable" и введите в поле Enter Bulletin Number следующую строчку:
ESXi600-201511401-BG
Нажмите Search, после чего скачайте обновленный билд VMware ESXi 6.0 по кнопке Download:
Про патч в формате VIB-пакета написано вот тут, а про сам обновленный релиз ESXi вот тут. Для установки VIB на сервере ESXi используйте следующую команду:
Сегодняшняя статья расскажет вам ещё об одной функции моего PowerShell-модуля для управления виртуальной инфраструктурой VMware - Vi-Module. Первая статья этой серии с описанием самого модуля находится здесь. Функция Convert-VmdkThin2EZThick. Как вы уже поняли из её названия, функция конвертирует все «тонкие» (Thin Provision) виртуальные диски виртуальной машины в диски типа Thick Provision Eager Zeroed.
Многие из вас знают, что в VMware vSphere есть такой режим работы виртуальных дисков, как Raw Device Mapping (RDM), который позволяет напрямую использовать блочное устройство хранения без создания на нем файловой системы VMFS. Тома RDM бывают pRDM (physical) и vRDM (virtual), то есть могут работать в режиме физической и виртуальной совместимости. При работе томов в режиме виртуальной совместимости они очень похожи на VMFS-тома (и используются очень редко), а вот режим физической совместимости имеет некоторые преимущества перед VMFS и довольно часто используется в крупных предприятиях.
Итак, для чего может быть полезен pRDM:
Администратору требуется использовать специальное ПО от производителя массива, которое работает с LUN напрямую. Например, для создания снапшотов тома, реплики базы данных или ПО, работающее с технологией VSS на уровне тома.
Старые данные приложений, которые еще не удалось перенести в виртуальные диски VMDK.
Виртуальная машина нуждается в прямом выполнении команд к тому RDM (например, управляющие SCSI-команды, которые блокируются слоем SCSI в VMkernel).
Перейдем к рассмотрению схемы решения VMware Site Recovery Manager (SRM):
Как вы знаете, продукт VMware SRM может использовать репликацию уровня массива (синхронную) или технологию vSphere Replication (асинхронную). Как мы писали вот тут, если вы используете репликацию уровня массива, то поддерживаются тома pRDM и vRDM, а вот если vSphere Replication, то репликация физических RDM будет невозможна.
Далее мы будем говорить о репликации уровня дискового массива томов pRDM, как о самом часто встречающемся случае.
Если говорить об уровне Storage Replication Adapter (SRA), который предоставляется производителем массива и которым оперирует SRM, то SRA вообще ничего не знает о томах VMFS, то есть о том, какого типа LUN реплицируется, и что на нем находится.
Он оперирует понятием только серийного номера тома, в чем можно убедиться, заглянув в XML-лог SRA:
Тут видно, что после серийного номера есть еще и имя тома - в нашем случае SRMRDM0 и SRMVMFS, а в остальном устройства обрабатываются одинаково.
SRM обрабатывает RDM-диски похожим на VMFS образом. Однако RDM-том не видится в качестве защищаемых хранилищ в консоли SRM, поэтому чтобы добавить такой диск, нужно добавить виртуальную машину, к которой он присоединен, в Protection Group (PG).
Допустим, мы добавили такую машину в PG, а в консоли SRM получили вот такое сообщение:
Device not found: Hard disk 3
Это значит одно из двух:
Не настроена репликация RDM-тома на резервную площадку.
Репликация тома настроена, но SRM еще не обнаружил его.
В первом случае вам нужно заняться настройкой репликации на уровне дискового массива и SRA. А во втором случае нужно пойти в настройки SRA->Manage->Array Pairs и нажать там кнопку "Обновить":
Этот том после этого должен появиться в списке реплицируемых устройств:
Далее в настройках защиты ВМ в Protection Group можно увидеть, что данный том видится и защищен:
Добавление RDM-диска к уже защищенной SRM виртуальной машине
Если вы просто подцепите диск такой ВМ, то увидите вот такую ошибку:
There are configuration issues with associated VMs
Потому, что даже если вы настроили репликацию RDM-диска на уровне дискового массива и SRA (как это описано выше), он автоматически не подцепится в настройки - нужно запустить редактирование Protection Group заново, и там уже будет будет виден RDM-том в разделе Datastore groups (если репликация корректно настроена):
Помните также, что SRM автоматически запускает обнаружение новых устройств каждые 24 часа по умолчанию.
Этой статьёй я хочу открыть серию статей, целью каждой из которых будет описание одной из написанных мной функций PowerCLI или так называемых командлетов (cmdlets), предназначенных для решения задач в виртуальных инфраструктурах, которые невозможно полноценно осуществить с помощью только лишь встроенных функций PowerCLI. Все эти функции будут объединены в один модуль - Vi-Module. Как им пользоваться, можете почитать здесь.
Интересный пост, касающийся поддержки VMware Tools в смешнном окружении, опубликовали на блогах VMware. Если вы взглянете на папку productLocker в ESXi, то увидите там 2 подпапки /vmtools и /floppies:
Это файлы, относящиеся к пакету VMware Tools, устанавливаемому в гостевые ОС виртуальных машин. Перейдем в папку /vmtools:
Тут находится куча ISO-образов с данными пакета (каждый под нужную гостевую ОС), файл манифеста, описывающий имена, версии и ресурсы файлов пакета, а также сигнатура ISO-шки с тулзами, позволяющая убедиться, что она не была изменена.
В папке floppies находятся виртуальные образы дискет, которые могут понадобиться для специфических гостевых ОС при установке драйверов (например, драйвер устройства Paravirtual SCSI):
Интересно, что папка productLocker занимает примерно 150 МБ, что составляет где-то половину от размера установки VMware ESXi. Именно поэтому рекомендуют использовать образ ESXi без VMware Tools ("no-tools") при использовании механизма Auto Deploy для массового развертывания хост-серверов.
Самая соль в том, что версия пакета VMware Tools на каждом хосте разная и зависит от версии VMware ESXi. Например, мы поставили на хосте VMware vSphere 5.5 виртуальную машину и установили в ней тулзы. Консоль vCenter покажет нам, что установлена последняя версия VMware Tools:
Однако если у нас смешанная инфраструктура (то есть, состоит их хостов разных версий), то при перемещении машины на хост с более высокой версией, например, vSphere 5.5 Update 2/3, она будет показана как ВМ с устаревшей версией пакета (VMware Tools: Running (Out-of-Date):
Поэтому возникает некоторая проблема в смешанной среде, которую можно решить очень просто - как правило VMware Tools от хоста с большей версией подходят ко всем предыдущим. Например, тулзы от vSphere 6.0 подойдут ко всем хостам до ESXi 4.0 включительно. vSphere 6 Update 1 выпадает из списка (постепенно поддержка старых версий уходит):
Таким образом, лучше всего распространить тулзы от vSphere 6 на все хосты вашей виртуальной инфраструктуры. Для этого создадим общий для всех хостов датастор SDT и через PowerCLI проверим, что к нему имеет доступ несколько хостов, командой:
Get-Datastore | where {$_.ExtensionData.summary.MultipleHostAccess -eq “true”}
Далее создадим на этом датасторе папку productLocker:
в которую положим VMware Tools от ESXi 6.0:
Далее нужно пойти в раздел:
Manage > Settings > Advanced System Settings > UserVars.ProductLockerLocation
и вбить туда путь к общей папке, в нашем случае такой:
/vmfs/volumes/SDT/productLocker
Если вы хотите применить эту настройку сразу же на всех хостах кластера, то можно использовать следующий командлет PowerCLI:
Теперь для применения настроек есть два пути: первый - это перезапустить хост ESXi, но если вы этого сделать не можете, то есть и второй путь - выполнить несколько команд по SSH.
Зайдем на хост ESXi через PuTTY и перейдем в папку с /productLocker командой cd. Вы увидите путь к локальной папке с тулзами на хосте, так как это ярлык:
Удалим этот ярлык:
rm /productLocker
После чего создадим новый ярлык на общую папку на томе VMFS с тулзами от vSphere 6.0:
Вот таким вот образом можно поддерживать самую последнюю версию VMware Tools в виртуальных машинах, когда в вашей производственной среде используются различные версии VMware ESXi.
Недавно Cormac Hogan написал интересный пост о том, как нужно настраивать "растянутый" между двумя площадками HA-кластер на платформе VMware vSphere, которая использует отказоустойчивую архитектуру Virtual SAN.
Напомним, как это должно выглядеть (два сайта на разнесенных площадках и witness-хост, который обрабатывает ситуации разделения площадок):
Основная идея такой конфигурации в том, что при отказе отдельного хоста или его компонентов виртуальная машина обязательно должна запуститься на той же площадке, где и была до этого, а в случае отказа всей площадки (аварии) - машины должны быть автоматически запущены на резервном сайте.
Откроем настройки кластера HA. Во-первых, он должен быть включен (Turn on vSphere HA), и средства обнаружения сетевых отказов кластера (Host Monitoring) также должны быть включены:
Host Monitoring позволяет хостам кластера обмениваться сигналами доступности (heartbeats) и в случае отказа предпринимать определенные действия с виртуальными машинами отказавшего хоста.
Для того, чтобы виртуальная машина всегда находилась на своей площадке в случае отказа хоста (и использовала локальные копии данных на виртуальных дисках VMDK), нужно создать Affinity Rules, которые определяют правила перезапуска ВМ на определенных группах хостов в рамках соответствующей площадки. При этом эти правила должны быть "Soft" (так называемые should rules), то есть они будут соблюдаться при возможности, но при отказе всей площадки они будут нарушены, чтобы запустить машины на резервном сайте.
Далее переходим к настройке "Host Hardware Monitoring - VM Component Protection":
На данный момент кластер VSAN не поддерживает VMCP (VM Component Protection), поэтому данную настройку надо оставить выключенной. Напомним, что VMCP - это новая функция VMware vSphere 6.0, которая позволяет восстанавливать виртуальные машины на хранилищах, которые попали в состояние All Paths Down (APD) или Permanent Device Loss (PDL). Соответственно, все что касается APD и PDL будет выставлено в Disabled:
Теперь посмотрим на картинку выше - следующей опцией идет Virtual Machine Monitoring - механизм, перезапускающий виртуальную машину в случае отсутствия сигналов от VMware Tools. Ее можно использовать или нет по вашему усмотрению - оба варианта полностью поддерживаются.
На этой же кариинке мы видим настройки Host Isolation и Responce for Host Isolation - это действие, которое будет предпринято в случае, если хост обнаруживает себя изолированным от основной сети управления. Тут VMware однозначно рекомендует выставить действие "Power off and restart VMs", чтобы в случае отделения хоста от основной сети он самостоятельно погасил виртуальные машины, а мастер-хост кластера HA дал команду на ее восстановление на одном из полноценных хостов.
Далее идут настройки Admission Control:
Здесь VMware настоятельно рекомендует использовать Admission Control по простой причине - для растянутых кластеров характерно требование самого высокого уровня доступности (для этого он, как правило, и создается), поэтому логично гарантировать ресурсы для запуска виртуальных машин в случае отказа всей площадки. То есть правильно было бы зарезервировать 50% ресурсов по памяти и процессору. Но можно и не гарантировать прям все 100% ресурсов в случае сбоя, поэтому можно здесь поставить 30-50%, в зависимости от требований и условий работы ваших рабочих нагрузок в виртуальных машинах.
Далее идет настройка Datastore for Heartbeating:
Тут все просто - кластер Virtual SAN не поддерживает использование Datastore for Heartbeating, но такого варианта тут нет :) Поэтому надо выставить вариант "Use datastores only from the secified list" и ничего из списка не выбирать (убедиться, что ничего не выбрано). В этом случае вы получите сообщение "number of vSphere HA heartbeat datastore for this host is 0, which is less than required:2".
Убрать его можно по инструкции в KB 2004739, установив расширенную настройку кластера das.ignoreInsufficientHbDatastore = true.
Далее нужно обязательно установить кое-какие Advanced Options. Так как кластер у нас растянутый, то для обнаружения наступления события изоляции нужно использовать как минимум 2 адреса - по одному на каждой площадке, поэтому расширенная настройка das.usedefaultisolationaddress должна быть установлена в значение false. Ну и нужно добавить IP-адреса хостов, которые будут пинговаться на наступление изоляции хост-серверов VMware ESXi - это настройки das.isolationaddress0 и das.isolationaddress1.
Таким образом мы получаем следующие рекомендуемые настройки растянутого кластера HA совместно с кластером Virtual SAN:
vSphere HA
Turn on
Host Monitoring
Enabled
Host Hardware Monitoring – VM Component Protection: “Protect against Storage Connectivity Loss”
Disabled (по умолчанию)
Virtual Machine Monitoring
Опционально, по умолчанию "Disabled"
Admission Control
30-50% для CPU и Memory.
Host Isolation Response
Power off and restart VMs
Datastore Heartbeats
Выбрать "Use datastores only from the specified list", но не выбирать ни одного хранилища из списка
Ну и должны быть добавлены следующие Advanced Settings:
Автоматическая установка сама по себе несложный процесс, хотя и требует некоторых базовых знаний. Сложно здесь другое – развернуть вспомогательную инфраструктуру для загрузки по сети, включающую в себя PXE, TFTP и DHCP сервера и настроить её должным образом. А для этого, во-первых, нужно обладать глубокими техническими знаниями во многих областях и, во-вторых, это требует длительных временных затрат, ну и, в-третьих, это не всегда возможно в связи с внутриорганизационной политикой. Таги: VMware, ESXi, Kickstart, Automation, Hardware, vSphere, PowerShell
На днях компания Veeam выпустила обновленную версию продукта для комплексного мониторинга и решения проблем в виртуальной среде Veeam Management Pack v8 for System Center.
Новые возможности Veeam Management Pack v8 for System Center:
App-to-metal visibility
Это основная функция решения, которая позволяет организовать отслеживание всех компонентов физической и виртуальной инфраструктуры и связей между ними. Ниже раскрывается сущность этих улучшений, в следующих версиях эти функции будут совершенствоваться.
Полная поддержка VMware vSphere 6 - теперь поддерживаются все новые возможности, такие как Virtual Volumes Datastores (VVOLs), компоненты vCenter, лицензирования и сетевого взаимодействия.
Улучшения Veeam Task Manager for Hyper-V - в новом таск-менеджере поддерживаются виртуальные машины на хранилищах SMB 3.0, а также новые метрики, такие как CPU dispatch time. Кроме того, теперь есть представления кластера Hyper-V и полная совместимость с метриками System Center Virtual Machine Manager и Operations Manager.
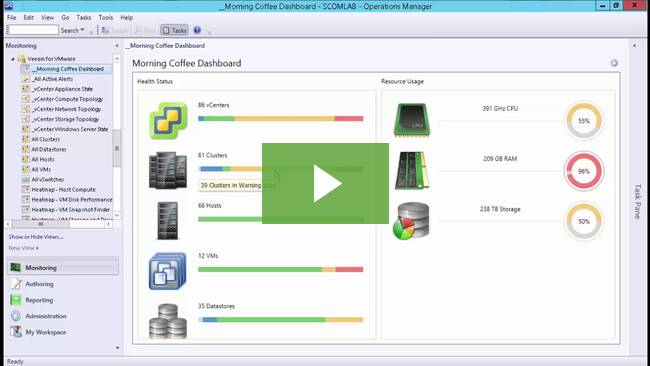
Veeam Morning Coffee Dashboard - новое представление с удобной суммарной информацией по инфраструктуре, на которое первым делом смотрит системный администратор за чашкой утреннего кофе. Отчет Morning Coffee содержит такие показатели, как "VM density" (плотность ВМ на хосте) и уровень нагрузки на вычислительные ресурсы и системы хранения.
Capacity planning and right sizing - теперь функции планирования мощностей виртуальной инфраструктуры значительно расширились и теперь содержат следующие сценарии и представления:
- Host Failure Modeling (моделирование ситуации отказа хоста)
- Performance Forecast for vSphere Datastores (прогноз производительности для хранилищ vSphere)
- Performance Forecast for Hyper-V Storage (прогноз производительности для систем хранения Hyper-V)
- Performance Forecast for vSphere and Hyper-V Clusters (прогноз производительности для кластеров vSphere и Hyper-V)
- Virtual Machine Capacity Prediction (прогноз использования ресурсов виртуальными машинами)
- Resize VMs to reclaim resources (перераспределение ресурсов виртуальных машин)
- Capacity planning for hybrid cloud (планирование ресурсов для гибридного облака)
- Capacity planning for Veeam Backup Repositories (планирование ресурсов для репозиториев Veeam Backup & Replication)
Улучшения планирования для Microsoft Azure или VMware vCloud Air
Отчет для планирования ресурсов был обновлен в соответствии с особенностями Azure и vCloud Air, и теперь с его помощью можно точно прогнозировать количество и тип ресурсов для переноса рабочих нагрузок в облако.
Улучшения отслеживания снапшотов
Забытые снапшоты и контрольные точки могут быстро разрастаться, занимать дисковое пространство и снижать производительность системы. С помощью "тепловых карт" (heat maps) вы сможете узнать, для каких виртуальных машин есть снапшоты и контрольные точки. Также доступен подробный отчет по иерархии снимков состояния, с указанием даты создания и комментариев.
Прочие улучшения:
Улучшенная визуализация топологий виртуальных ресурсов
Улучшенная видимость объектов Veeam Backup and Replication
Больше подробностей о Veeam Management Pack v8 for System Center на русском языке можно узнать на этой странице. Скачать продукт можно по этой ссылке.
Таги: Veeam, MP, Update, Microsoft, Hyper-V, System Center, SC VMM, Monitoring
Это гостевой пост компании ИТ-ГРАД. В нашу эпоху бурного роста объемов информации и «хотелок» бизнеса подход к сохранности данных тоже требует перемен. Вспомните, как раньше небольшие и средние компании решали вопрос с временной недоступностью своих сервисов. Если кратко — то никак. Полагались на авось и резервные копии. Сейчас же рост популярности виртуализации и облачных вычислений фактически уравнял в возможностях компании с любыми бюджетами.
Посмотрим, какие есть варианты организации катастрофоустойчивого решения с использованием облаков.
Компания VMware в своем блоге затронула интересную тему - обновление микрокода для процессоров платформ Intel и AMD в гипервизоре VMware ESXi, входящем в состав vSphere. Суть проблемы тут такова - современные процессоры предоставляют возможность обновления своего микрокода при загрузке, что позволяет исправлять сделанные вендором ошибки или устранять проблемные места. Как правило, обновления микрокода идут вместе с апдейтом BIOS, за которые отвечает вендор процессоров (Intel или AMD), а также вендор платформы (HP, Dell и другие).
Между тем, не все производители платформ делают обновления BIOS своевременно, поэтому чтобы получить апдейт микрокода приходится весьма долго ждать, что может быть критичным если ошибка в текущей версии микрокода весьма серьезная. ESXi имеет свой механизм microcode loader, который позволяет накатить обновления микрокода при загрузке в том случае, если вы получили эти обновления от вендора и знаете, что делаете.
Надо сказать, что в VMware vSphere 6.0 обновления микрокода накатываются только при загрузке и только на очень ранней стадии, так как более поздняя загрузка может поменять данные, уже инициализированные загрузившимся VMkernel.
Сама VMware использует тоже не самые последние обновления микрокода процессоров, так как в целях максимальной безопасности накатываются только самые критичные апдейты, а вендоры платформ просят время на тестирование обновлений.
Есть два способа обновить микрокод процессоров в ESXi - через установку VIB-пакета и через обновление файлов-пакетов микрокода на хранилище ESXi. Если вы заглянете в папку /bootbank, то увидите там такие файлы:
uc_amd.b00
uc_intel.b00
Эти файлы и содержат обновления микрокода и идут в VIB-пакете cpu-microcode гипервизора ESXi. Ниже опишем процедуру обновления микрокода для ESXi с помощью обоих методов. Предпочтительный метод - это делать апдейт через VIB-пакет, так как это наиболее безопасно. Также вам потребуется Lunix-машина для манипуляций с микрокодом. Все описанное ниже вы делаете только на свой страх и риск.
После распаковки вы получите файл microcode.dat. Это файл в ASCII-формате, его надо будет преобразовать в бинарный. У AMD в репозитории есть сразу бинарные файлы (3 штуки, все нужные).
2. Делаем бинарный пакет микрокода.
Создаем следующий python-скрипт и называем его intelBlob.py:
#! /usr/bin/python
# Make a raw binary blob from Intel microcode format.
# Requires Python 2.6 or later (including Python 3)
# Usage: intelBlob.py < microcode.dat microcode.bin
import sys
outf = open(sys.argv[1], "wb")
for line in sys.stdin:
if line[0] == '/':
continue
hvals = line.split(',')
for hval in hvals:
if hval == '\n' or hval == '\r\n':
continue
val = int(hval, 16)
for shift in (0, 8, 16, 24):
outf.write(bytearray([(val >> shift) & 0xff]))
Тут все просто. Выполним одну из следующих команд для полученных файлов:
cp uc_intel.gz /bootbank/uc_intel.b00
cp uc_amd.gz /bootbank/uc_amd.b00
Далее можно переходить к шагу 5.
4. Метод создания VIB-пакета и его установки.
Тут нужно использовать утилиту VIB Author, которую можно поставить на Linux-машину (на данный момент утилита идет в RPM-формате, оптимизирована под SuSE Enterprise Linux 11 SP2, который и предлагается использовать). Скачайте файл cpu-microcode.xml и самостоятельно внесите в него изменения касающиеся версии микрокода.
Затем делаем VIB-пакет с помощью следующей команды:
Затем проверьте наличие файлов uc_*.b00, которые вы сделали на шаге 2, в директории /altbootbank.
5. Тестирование.
После перезагрузки хоста ESXi посмотрите в лог /var/log/vmkernel.log на наличие сообщений MicrocodeUpdate. Также можно посмотреть через vish в файлы /hardware/cpu/cpuList/*, в которых где-то в конце будут следующие строчки:
Number of microcode updates:1
Original Revision:0x00000011
Current Revision:0x00000017
Это и означает, что микрокод процессоров у вас обновлен. ESXi обновляет микрокод всех процессоров последовательно. Вы можете проверит это, посмотрев параметр Current Revision.
Также вы можете запретить на хосте любые обновления микрокода, установив опцию microcodeUpdate=FALSE в разделе VMkernel boot. Также по умолчанию запрещено обновление микрокода на более ранние версии (даунгрейд) и на экспериментальные версии. Это можно отключить, используя опцию microcodeUpdateForce=TRUE (однако микрокод большинства процессоров может быть обновлен только при наличии цифровой подписи вендора). Кроме того, чтобы поставить экспериментальный апдейт микрокода, нужно включить опции "debug mode" или "debug interface" в BIOS сервера, после чего полностью перезагрузить его.
Некоторое время назад мы писали про обработку гипервизором VMware vSphere таких состояний хранилища ВМ, как APD (All Paths Down) и PDL (Permanent Device Loss). Вкратце: APD - это когда хост-сервер ESXi не может получить доступ к устройству ни по одному из путей, а также устройство не дает кодов ответа на SCSI-команды, а PDL - это когда хост-серверу ESXi удается понять, что устройство не только недоступно по всем имеющимся путям, но и удалено совсем, либо сломалось.
Так вот, в новой версии VMware vSphere 6.0 появился механизм VM Component Protection (VMCP), который позволяет обрабатывать эти ситуации со стороны кластера высокой доступности VMware HA в том случае, если в нем остались другие хосты, имеющие доступ к виртуальной машине, оставшейся без "хост-хозяина".
Для того чтобы это начало работать, нужно на уровне кластера включить настройку "Protect against Storage Connectivity Loss":
Далее посмотрим на настройки механизма Virtual Machine Monitoring, куда входят и настройки VM Component Protection (VMCP):
С ситуацией PDL все понятно - хост больше не имеет доступа к виртуальной машине, и массив знает об этом, то есть вернул серверу ESXi соответствующий статус - в этом случае разумно выключить процесс машины на данном хосте и запустить ВМ на других серверах. Тут выполняется действие, указанное в поле Response for a Datastore with Permanent Device Loss (PDL).
Со статусом же APD все происходит несколько иначе. Поскольку в этом состоянии мы не знаем пропал ли доступ к хранилищу ВМ ненадолго или же навсегда, происходит все следующим образом:
возникает пауза до 140 секунд, во время которой хост пытается восстановить соединение с хранилищем
если связь не восстановлена, хост помечает датастор как недоступный по причине APD Timout
далее VMware HA включает счетчик времени, который длится ровно столько, сколько указано в поле Delay for VM failover for APD (по умолчанию - 3 минуты)
по истечении этого времени начинается выполнение действия Response for a Datastore with All Paths Down (APD), а само хранилище помечается как утраченное (NO_Connect)
У такого механизма работы есть следующие особенности:
VMCP не поддерживает датасторы Virtual SAN - они будут просто игнорироваться.
VMCP не поддерживает Fault Tolerance. Машины, защищенные этой технологией, будут получать перекрывающую настройку не использовать VMCP.
Не так давно мы писали про технологию Virtual Volumes (VVols), которая полноценно была запущена в новой версии платформы виртуализации VMware vSphere 6. VVols - это низкоуровневое хранилище для виртуальных машин, с которым позволены операции на уровне массива по аналогии с теми, которые доступны для традиционных LUN - например, снапшоты дискового уровня, репликация и прочее.
VVols - это один из типов хранилищ (Datastore) в vSphere:
Тома vVOLs создаются на дисковом массиве при обращении платформы к новой виртуальной машине (создание, клонирование или снапшот). Для каждой виртуальной машины и ее файлов, которые вы сейчас видите в папке с ВМ, создается отдельный vVOL.
Многие администраторы задаются вопросом: а почему VVols - это крутая штука, нужны ли они вообще? VMware в своем блоге отвечает на этот вопрос. Попробуем изложить их позицию здесь вкратце.
Ну, во-первых, VVols дают возможность создавать аппаратные снапшоты, клоны и снапклоны на уровне одной виртуальной машины, а не целых LUN, но это неконцептуально. Вопрос следует понимать глубже.
Все идет из концепции SDDC (Software Defined Datacenter), которая подразумевает абстракцию всех уровней аппаратных компонентов (вычислительные ресурсы, сети, хранилища) на программный уровень таким образом, чтобы администратор виртуальных ресурсов не ломал себе голову насчет физического устройства датацентра при развертывании новых систем. Иными словами, при создании виртуальной машины администратор должен определить требования к виртуальной машине в виде политики (например система Tier 1), а программно-определяемый датацентр сам решит где и как эту машину разместить (хост+хранилище) и подключить ее к сети (тут вспомним про продукт VMware NSX).
С точки зрения хранилищ (SDS - software defined storage) эта концепция реализуется через подход Storage Policy Based Management (SPBM), предполагающий развертывание новых систем на хранилищах, которые описаны политиками. Этого мы уже касались в статье "VMware vSphere Storage DRS и Profile Driven Storage - что это такое и как работает".
Если раньше дисковый массив определял возможности хранилища, на котором размещалась ВМ (через LUN для Datastore), и машина довольствовалась тем, что есть, то теперь подход изменился: с Virtual Volumes, к которым привязаны политики виртуальных машин, сама машина "рассказывает" о своих требованиях дисковому массиву, который уже ищет, где он может ее "поселить". Этот подход является более правильным с точки зрения автоматизации и человеческого фактора (ниже расскажем почему).
Представим, что у нас есть три фактора, которые определяют качество хранилища:
Тип избыточности и размещения данных (например, RAID - Stripe/Mirror)
Наличие дедупликации (да/нет)
Тип носителя (Flash/SAS/SATA)
Это нам даст 12 возможных комбинаций типов LUN, которые мы можем создать на дисковом массиве:
Соответственно, чтобы учесть все такие комбинации требований при создании виртуальных хранилищ (Datastores), мы должны были бы создать 12 LUN. Но на этом проблемы только начинаются, так как администратор всегда стремится выбрать лучшее с его точки зрения доступное хранилище, что может привести к тому, что LUN1 у нас будет заполнен под завязку системами разной критичности, а новые критичные системы придется размещать на LUN более низкого качества.
На помощь тут приходят политики хранилищ (VM Storage Policies). Например, мы создаем политики Platinum, Silver и Gold, для которых определяем необходимые поддерживаемые хранилищами функции, которые обоснованы, например, критичностью систем:
Если говорить о примере выше, то Platinum - это, например, хранилище с характеристиками LUN типов 1 и 3.
Интерфейс vSphere Web Client нам сразу показывает совместимые и несовместимые с этими политиками хранилища:
Так вот при развертывании новой ВМ администратору должно быть более-менее неважно, на каком именно массиве или LUN будет расположена машина, он должен будет просто выбрать политику, которая отражает его требования к хранилищу. Удобно же!
При создании политики администратор просто выбирает провайдера сервисов хранения (в данном случае массив NetApp с поддержкой VVols) и определяет необходимые поддерживаемые фичи для набора правил в политике:
После этого при развертывании новой виртуальной машины администратор просто выбирает нужную политику, зная обеспечиваемый ей уровень обслуживания, и хранилищем запускается процесс поиска места для новой ВМ (а точнее, ее объектов) в соответствии с определенными в политике требованиями. Если эти требования возможно обеспечить, то создаются необходимые тома VVOls (как бы отдельные LUN для объектов машины). Таким образом, с помощью политик машины автоматически "вселяются" в пространство хранения дисковых массивов в соответствии с требованиями, не позволяя субъективному человеку дисбалансировать распределение машин по хранилищам различных ярусов. Вот тут и устраняется человеческий фактор, и проявляется сервисно-ориентированный подход: не машину "селят" куда скажет дядя-админ, а система выбирает хранилище для ВМ, которое соответсвует ее требованиям.
Вскоре после релиза новой версии платформы виртуализации VMware vSphere 6.0 компания VMware объявила о доступности для загрузки обновленного решения VMware Site Recovery Manager 6.0, предназначенного для создания катастрофоустойчивой виртуальной инфраструктуры. Напомним, что о возможностях прошлой версии - VMware SRM 5.8 - мы писали вот тут.
В продукте VMware SRM 6.0 появилось четыре основных улучшения:
1. Улучшенная совместимость с Storage DRS и Storage vMotion.
Ранее была только базовая совместимость с этими продуктами - во-первых, при перемещении с помощью SVMotion машины из consistency group, защищенной SRM, не выводилось никакого предупреждения (теперь есть), а, во-вторых, теперь Datastore Cluster в SDRS поддерживает несколько consistency groups, защищенных SRM:
То есть, как бы получается, что теперь между этими всеми продуктами полная совместимость, и решение можно использовать более гибко.
2. Упрощенные требования в SSL-сертификатам.
Теперь SRM 6.0 полностью интегрирован со службами vSphere 6.0 platform services (SSO, Authorization, Licensing, Tags и прочее), что делает удобным развертывание и установку сертификатов SSL для безопасного взаимодействия компонентов.
3. Полная поддержка VMware vSphere 6.0.
SRM 6.0 теперь поддерживается в связке со следующими компонентами:
vCenter Server 6.0
vSphere Web Client 6.0
vSphere Replication, version 6.0 (если используется)
Большинство SRA (Storage Replication Adapters), которые поддерживались в версии SRM 5.8, продолжают поддерживаться и в 6.0. Для точной информации смотрите Compatibility Guide.
Все максимальные лимиты vSphere 6.0 также поддерживаются и со стороны SRM 6.0. Кроме того, теперь стали доступны для развертывания различные топологии совместно с SRM, описанные вот тут. Об этом постараемся написать вскоре подробнее.
4. Улучшения IP-кастомизации.
Утилита dr-ip-customizer теперь при кастомизации IP-адреса виртуальной машины обновляет как IPv4, так и IPv6 спецификацию. Кроме того, в этом плане поддерживается обратная совместимость с версиями SRM 5.x.
Скачать VMware Site Recovery Manager 6.0 можно по этой ссылке.
Продолжаем рассказывать о возможностях новой версии серверной платформы виртуализации VMware vSphere 6, выход которой ожидается в ближайшее время. Напомним наши последние посты на эту тему:
Сегодня у нас на очереди одна из самых интересных тем в vSphere 6 - технология организации хранилищ VMware vSphere Virtual Volumes (VVOls). Напомним, что ранее мы подробно писали о ней тут. С тех пор появилось некоторое количество новой информации, которую мы постараемся актуализировать и дополнить в этом посте.
Начнем с того, что vVOL - это низкоуровневое хранилище для виртуальных машин, с которым позволены операции на уровне массива по аналогии с теми, которые сегодня доступны для традиционных LUN - например, снапшоты дискового уровня, репликация и прочее. vVOLs - это новый способ организации хранилищ в виде удобном для массива, когда используется не традиционная файловая система VMFS, а массив сам определяет, каким образом решать задачи доступа и организации работы с данными для виртуальных машин.
Тома vVOLs создаются на дисковом массиве при обращении платформы к новой виртуальной машине (создание, клонирование или снапшот). Для каждой виртуальной машины и ее файлов, которые вы сейчас видите в папке с ВМ, создается отдельный vVOL. В итоге же, создаются следующие тома на хранилище:
1 config vVOL создается для метаданных ВМ, он включает в себя конфигурационный файл .vmx, дескрипторные vmdk для виртуальных дисков, лог-файлы и прочие вспомогательные файлы.
1 vVOL создается для каждого виртуального диска .VMDK.
1 vVOL создается для файла подкачки, если это требуется.
1 vVOL создается для каждого снапшота и для каждого снимка оперативной памяти.
Дополнительные тома vVOL могут быть созданы для клонов или реплик виртуальной машины.
Давайте посмотрим на архитектуру VVols:
Здесь мы видим следующие компоненты:
Storage Provider (SP)
Технология vVOLs при взаимодействии с аппаратным хранилищем реализуется компонентом Storage Provider (SP), который также называется VASA Provider (подробнее об интерфейсе VASA - тут). Storage provider - это предоставляемый вендором аппаратного обеспечения слой ПО, который обеспечивает взаимодействие платформы vSphere и, собственно, хранилища с организованными на нем томами vVOLs в виде контейнеров (storage containers). vVOLs используют механизм VASA 2.0, который позволяет управлять объектами виртуальных машин (дискми) прямо на хранилище.
Protocol EndPoint (PE)
Если раньше каждый хост налаживал в случае необходимости соединение с каждым из vmdk-дисков виртуальных машин и получалось куча связей, то теперь у хранилища есть логическое I/O-устройство, через которое происходит общение с томами vVOL. PE можно считать сущностью, пришедшей на замену LUN, этих PE может быть создано сколько угодно (кстати, длина очереди у PE - 128 по умолчанию, вместо 32 у LUN).
То есть, через PE хост ESXi получает доступ к данным конкретной виртуальной машины. PE совместимы с существующими протоколами FC, iSCSI и NFS и позволяют использовать уже имеющееся ПО для управления путями в SAN. К отдельному PE через vCenter можно привязать или отвязать тома vVOL отдельных виртуальных машин. Для хранилища не нужно много PE, одно это логическое устройство может обслуживать сотни и тысячи виртуальных томов vVOL.
Storage Container (SC)
Это логическая сущность, которая нужна для объединения томов vVOL по типам в целях выполнения административных задач. Storage Container создается и управляется на стороне дискового массива и предназначен для логической группировки и изоляции виртуальных машин (например, виртуальные машины отдельного клиента в публичном облаке vCloud).
vVOL Datastore
Это хранилище, которое непосредственно создается из vSphere Client. По-сути, это представление Storage Container (SC) для платформы VMware vSphere. Этот тип датастора можно, например, выбрать при создании виртуальной машины:
С точки зрения администрирования, эти датасторы аналогичны VMFS-томам - вы так же можете просматривать их содержимое и размещать там виртуальные машины. Но для них недоступны операции расширения или апгрейда - они полностью контролируются со стороны дискового массива.
Policy Based Management
Это механизм, который позволяет назначать виртуальным машинам политики, которые определяют ее размещение, а как следствие, и производительность с точки зрения подсистемы ввода-вывода (например, можно задавать необходимые трешхолды по ReadOPs, WriteOPs, ReadLatency и WriteLatency.).
Дисковый массив на базе этих политик позволяет разместить виртуальную машину на нужном хранилище и обеспечить необходимые операции по обеспечению нужного уровня производительности.
По прочтении этого материала возникает вопрос - а чем vVOLs лучше механизма VAAI, который уже давно существует для VMware vSphere? Ответ прост - это замена VAAI, которая позволяет еще больше функций по работе с виртуальными машинами и организации хранилищ переложить на сторону аппаратного обеспечения. В случае невозможности операций с vVOLs будет произведено переключение на использование примитивов VAAI:
Многие пользователи VMware Virtual SAN (VSAN), когда проводят тест бэкапа одной виртуальной машины, замечают, что время резервного копирования этой ВМ существенно больше, чем таковое для машины, размещенной на дисковом массиве.
Дункан в своем блоге подробно разбирает эту проблему. Тут дело вот в чем - когда вы используете дисковый массив, то виртуальная машина "размазывается" по дискам RAID-группы, что позволяет читать одновременно с нескольких дисков. Это дает хорошую производительность операции резервного копирования для одной машины.
Кластер же VSAN работает немного по-другому. Это объектное хранилище, в котором виртуальный диск ВМ хранится на одном хосте и его реплика существует на втором. Кроме этого, есть кэш на SSD-диске (но его еще нужно "прогреть"). То есть выглядит все это следующим образом:
Соответственно, при бэкапе одной виртуальной машины данные читаются только с двух HDD-дисков, а не с нескольких как в традиционной архитектуре дисковых массивов, при этом сам кластер VSAN может состоять из нескольких хостов (до 32 узлов). То есть, это архитектурное ограничение.
Однако если мы будем делать одновременный бэкап нескольких виртуальных машин с хранилища Virtual SAN время этой операции уже будет сравнимо с дисковым массивом, поскольку будет задействовано сразу несколько дисков на каждом из хостов, плюс хорошо прогреется кэш. Поэтому проведение такого теста (ведь он ближе к реальным условиям) и было бы более показательным при сравнении Virtual SAN и традиционных хранилищ.
То же самое относится и к VDI-инфраструктуре на базе VSAN - многие пользователи отмечают, что первая фаза операции Recompose (когда создается реплика - полный клон ВМ) отрабатывает весьма медленно. Однако если вы делаете много таких операций - кэш прогревается, и одновременное создание нескольких клонов начинает работать заметно быстрее в расчете на одну машину.
Как вы знаете, автор этого сайта придерживается правила "лучше переставлять, чем обновлять" (когда речь идет о мажорных версиях продукта - см., например, вот тут и тут).
В VMware vSphere 5.0 компания VMware обновила свою кластерную файловую систему до версии VMFS 5. При этом в vSphere 5.x тома VMFS-3 поддерживаются, а также доступен апгрейд с третьей версии на пятую (напомним, что в пятой версии появилась поддержка дисков в 64 ТБ). Более подробная информация об апгрейде VMFS приведена в документе "VMware vSphere VMFS-5 Upgrade Considerations".
Так вот, апгрейженный том VMFS-5 имеет ограниченную функциональность в отличие от созданного заново тома, а именно:
Апгрейженный том продолжает использовать исходный размер блока (в новой версии VMFS 5.x размер блока унифицирован - 1 МБ). Это иногда может привести к чрезмерному потреблению места на диске (если много мелких файлов), но что самое неприятное - к падению производительности Storage vMotion.
Апгрейженный том не имеет таких возможностей как Sub-Block Size, увеличенное число файлов на хранилище и разметка GPT.
Обновленный том VMFS-5 продолжает иметь раздел, начинающийся с сектора 128, это может вызвать некоторые проблемы с выравниванием блоков. Новый раздел VMFS 5 начинается с сектора 2048.
Таким образом, получается, что лучше создать новый том VMFS-5, чем обновлять существующие тома VMFS-3. Но это все было давно, ну а вдруг у вас остались такие вот обновленные VMFS, из-за которых у вас иногда что-то работает не так?
Проверить, какой у вас том, можно в vSphere Client или vSphere Web Client. Смотрим размер блока:
Если он не 1 МБ - то это точно апгрейженный том, и его неплохо бы пересоздать. А вот если 1 МБ, то вовсе не факт, что это новый том (как раньше, так и сейчас был такой размер блока). В этом случае вам поможет вот этот скрипт, который выводит список всех томов VMFS и показывает, новый это том или апгрейженный.
Запустить этот скрипт можно таким образом:
1. Загружаем его и переименовываем его в check_vmfs.sh, убрав расширение .doc.
2. Копируем скрипт на виртуальный модуль vMA. Можно также запускать скрипт локально на сервере ESXi - для этого его туда надо загрузить через Veeam FastSCP или WinSCP.
3. Включаем демон SSH на хостах ESXi, где вы будете выполнять скрипт. (в vSphere Client нужно зайти в Configuration \ Software \ Security profile \ Services \ SSH).
4. Удаленно выполнить скрипт на серверах через SSH можно с помощью команды:
ssh root@<ESXi IP> 'ash -s' < ./check_vmfs.sh
Далее попросят пароль и будет выведен результат работы скрипта.
Здесь нужно смотреть на значение Sub Blocks, если Sub Blocks = 3968, то это апгрейженный VMFS-5, и его неплохо бы пересоздать. У нормального VMFS-5 значение Sub Blocks равно 32000.
Такое вот работающее правило "лучше переставлять, чем обновлять". Любители PowerShell могут также посмотреть вот эту статью.
В этом посте специалисты компани ИТ-ГРАД расскажут о решении Cisco UCS Director и покажут как сделать так, чтобы конечные пользователи могли самостоятельно сформировать запрос на портале самообслуживания Cisco UCS Director и автоматически получить готовую виртуальную машину.
Для этого мы с вами научимся создавать наборы политик и объединять несколько политик в группу в рамках vDC, а также создадим каталог (шаблон) на базе этих политик, чтобы предоставить пользователям доступ к этому каталогу через портал самообслуживания.
Начнем с инфраструктуры. Инфраструктура, на базе которой мы будем выполнять все настройки, состоит из:
NetApp Clustered DataONTAP 8.2 Simulator в качестве дискового массива;
виртуальной инфраструктуры развернутой на базе:
ESXi appliance 5.5.0;
vCenter appliance 5.5.0a.
Выглядит это примерно так:
Сразу отмечу, что все настройки политик и параметров для шаблона(ов) виртуальных машин в нашем посте будут относиться к VMWare vSphere инфраструктуре..Читать статью далее
Как мы писали недавно, в новой версии платформы VMware vSphere 6, которая сейчас находится в стадии публичной беты, появились возможности использования томов VVols (о которых мы писали здесь). Сейчас эта функциональность также находится в бете и доступна для загрузки вот тут.
Концепция VVol (она же VM Volumes) увеличивает уровень гранулярности работы хост-сервера с хранилищем за счет непосредственных операций с виртуальной машиной, минуя сущности "LUN->том VMFS->Datastore". Тома VVol является неким аналогом существующих сегодня LUN, но с меньшим уровнем гранулярности операций по сравнению с томами VMFS (последние, как правило, создаются из одного LUN). Таким образом, ВМ находится на одном VVol как всадник на лошади.
Чтобы виртуальные машины можно было создавать на томах VVols и производить с ними различные операции, нужно чтобы дисковый массив поддерживал такой интерфейс как vSphere APIs for Storage Awareness (VASA). Через этот API возможна передача функций, обычно выполняемых хостом ESXi, на сторону аппаратного хранилища. Кроме того, есть также интерфейс vSphere Storage API – Array Integration (VAAI), который также используется для offloading'а операций на сторону массива, особенно когда дело касается операций миграции и клонирования ВМ.
Давайте посмотрим, как эти два API (VASA и VAAI) работают с хранилищем при операциях клонирования виртуальных машин, которые часто нужны в инфраструктуре виртуальных ПК на базе VMware Horizon View.
Сценарий 1 - клонирование ВМ в рамках одного контейнера VVol
В этом случае через API VASA вызывается функция cloneVirtualVolume, которая полностью передает на сторону дискового массива операцию клонирования ВМ:
Сценарий 2 - клонирование ВМ в рамках разных VVol
В этом случае все зависит от того, на каких хранилищах находятся данные VVol. Если VVol-a и VVol-b находятся на двух массивах одного вендора, настроенных единообразно, и управляются одним VASA Provider, то в этом случае используется API VASA и вызывается функция cloneVirtualVolume.
Если же VVol-a и VVol-b находятся на одном массиве и настроены по-разному, либо хранилища VVol-a и VVol-b находятся на двух массивах разных вендоров или моделей, то операция через VASA API может не пройти. Тогда происходит переключение на VAAI API, который использует датамувер ESXi (vmkernel data mover) и примитивы VAAI для клонирования виртуальной машины. При этом в случае неудачи передачи операций клонирования на сторону массива датамувер может начать перемещать данные через хост ESXi (подробнее - тут):
Конечно же, предпочтительнее делать все через VASA API - такая операция пройдет быстрее, поскольку в ней не будет задействован хост ESXi. Поэтому тут важна унификация конфигурации хранилищ и дисковых массивов в инфраструктуре. Ну и надо, конечно же, смотреть, чтобы закупаемые массивы в полной мере поддерживали VASA и VAAI.
Сценарий 3 - клонирование ВМ с тома VMFS на VVol
Если получается так, что ВМ надо склонировать с тома VMFS на хранилище VVol, то тут будет работать только операция XCOPY / WRITE_SAME интерфейса VAAI.
При этом работает это только для операции в направлении VMFS->VVol, при обратном клонировании этот API использован не будет.
Узнать больше о томах VVol и позадавать вопросы на эту тему вы можете на специальной странице Virtual Volumes beta community.
Как многие из вас знают, бета-версии платформы виртуализации VMware vSphere всегда были закрытыми, тестировал их очень ограниченный круг пользователей, находившихся под действием соглашения NDA (Non-disclosure agreement), которое подразумевало страшные кары и звонки юристов в случае его нарушения. В письмах с новостями о бета-версии были большие красные буквы про конфиденциальность, а за разглашение информации о новых возможностях продукта пытались наказать всех подряд, даже тех, кто этого соглашения не подписывал.
Возможно, компании VMware надоела вся эта канитель, и она впервые в своей истории решилась на открытое бета-тестирование VMware vSphere 6.0, но (видимо, по привычке) решила запретить публичное разглашение и обсуждение сведений о новой версии продукта.
For the first time, and unlike previous beta cycles for vSphere, this vSphere Beta is open to everyone to sign up and allows participants to help define the direction of the world’s most widely adopted, trusted, and robust virtualization platform.
Зарегистрировавшись в публичной бета-программе и подписав NDA, пользователи попадают в закрытое общество, где они могут обсуждать новые возможности платформы VMware vSphere, но им как бы запрещено это обсуждать с теми, кто не принимает участие в бете. Звучит как что-то очень параноидальное, но это так.
Итак, как участник VMware vSphere Beta Program вы можете:
Обсуждать продукт и саму программу с другими участниками бета-программы.
Постить в закрытые форумы на VMware Communities.
Общаться с вендорами серверного оборудования на эту тему (они тоже должны быть под NDA).
В то же время как участник VMware vSphere Beta Program вы не можете:
Обсуждать условия программы или новые возможности продукта публично.
Обсуждать программу приватно, но с теми людьми, которые не находятся под NDA.
В общем, можете сами теперь попробовать, что такое VMware vSphere 6.0 Beta 2. Нужно нажать кнопку "Join now!" в правой части, после чего принять VMware Master Software Beta Test Agreement (MSBTA) и vSphere Program Rules agreement. Бесспорно, публичная бета-кампания позволит VMware поднять качество своих продуктов, так как любой желающий сможет сообщить об ошибке, возникшей у него в тестовой среде.
Одновременно с анонсом публичной беты VMware vSphere 6.0 компания VMware раскрыла некоторые подробности о функциональности Virtual Volumes (VVols), о которой мы писали вот тут. Концепция VVol (она же VM Volumes) увеличивает уровень гранулярности работы хост-сервера с хранилищем за счет непосредственных операций с виртуальной машиной, минуя сущности "LUN->том VMFS->Datastore". Тома VVol является неким аналогом существующих сегодня LUN, но с меньшим уровнем гранулярности операций по сравнению с томами VMFS (последние, как правило, создаются из одного LUN).
То есть, VVol - это низкоуровневое хранилище одной виртуальной машины, с которым будут позволены операции на уровне массива, которые сегодня доступны для традиционных LUN - например, снапшоты дискового уровня, репликация и прочее. Делается это через механизм vSphere APIs for Storage Awareness (VASA). Таким образом, все необходимое хранилище виртуальной машины упаковывается в этот самый VVol. Более подробно о томах VVol можно узнать на специальной странице.
Само собой, такое должно поддерживаться со стороны производителей хранилищ, которые уже давно работают с VVol и записали несколько демок:
Tintri
SolidFire
HP
NetApp
EMC
Nimble Storage
Ну а вообще, конечно, это шаг вперед по сравнению с той паранойей VMware, которая была раньше вокруг бета-версий VMware vSphere.
Как многие из вас знают, в платформе виртуализации VMware vSphere есть множество удобных средств работы с хранилищами, включая средства позволяющие расширить том VMFS прямо из GUI клиента vSphere Client - достаточно лишь сделать Rescan HBA-адаптеров. Однако если необходимо расширить локальный том (Local VMFS), то тут встроенных средств уже нет, и все нужно аккуратно делать самому, как это описано в KB 2002461. Приведем здесь этот процесс, проиллюстрировав его скриншотами.
Как многие знают, с выходом средства для создания отказоустойчивых кластеров хранилищ VMware Virtual SAN, строящихся на базе локальных дисков серверов ESXi, стало известно, что этот механизм интегрирован со средством серверной отказоустойчивости VMware HA.
"Интегрирован" - означает, что любая нештатная ситуация, случившаяся с хостами ESXi должна быть обработана на стороне обоих механизмов, а также решение этой проблемы находится в компетенции поддержки VMware. И правда - ведь отказавший хост ESXi нарушает целостность обоих кластеров, поскольку предоставляет и ресурсы хранилищ, и вычислительные ресурсы.
При этом, например, в случае каких-нибудь сбоев в сети может произойти "разделение" кластеров на сегменты, что может повлечь неоднозначность в их поведении, поскольку они используют разные сети для поддержания кластера (хождения хартбитов).
Например, на картинке представлено разделение кластеров VMware HA и Virtual SAN на два частично пересекающихся сегмента:
Это, конечно же, плохо. Поэтому в VMware vSphere 5.5 были сделаны изменения, которые автоматически переносят сеть хартбитов кластера VMware HA в подсеть VMware Virtual SAN. Это позволяет в случае разделения сети иметь два непересекающихся в плане обоих технологий сегмента:
Как адрес в случае изоляции хоста (isolation address) нужно использовать, чтобы надежно отличать изоляцию хоста от разделения сети на сегменты (network partitioning)?
Какие действия в случае изоляции хостов ESXi от остальной сети (isolation responses) нужно использовать?
Ну а в статье на блогах VMware даются вот такие ответы:
1. В качестве хранилищ, использующих datastore heartbeat в данной конфигурации, предлагается использовать датасторы, прицепленные к хостам ESXi, не входящим в кластер Virtual SAN. Объясняется это тем, что в случае разделения сети VSAN, механизм VMware HA сможет координировать восстановление виртуальных машин на хостах через эти хранилища.
2. По поводу isolation address есть следующие рекомендации:
При совместном использовании Virtual SAN и vSphere HA настройте такой isolation address, который позволит определить рабочее состояние хоста в случае отключения его от сети (сетей) VSAN. Например, можно использовать шлюз VSAN и несколько дополнительных адресов, которые задаются через расширенную настройку das.isolationAddressX (подробнее об этом - тут).
Настройте HA так, чтобы не использовать дефолтный шлюз management network (если эта не та же сеть, что и Virtual SAN network). Делается это через настройку das.useDefaultIsolationAddress=false.
Ну и общая рекомендация - если вы понимаете, как может быть разделен кластер с точки зрения сети, то найдите такие адреса, которые будут доступны с любого хоста при этом сценарии.
3. Ну и самое главное - действие isolation response, которое необходимо выполнить в случае, когда хост посчитал себя изолированным от других. На эту тему уже много чего писалось, но VMware объединила это вот в такие таблички:
Тип виртуальной машины
Хост имеет доступ к сети VSAN?
Виртуальные машины имеют доступ к своей сети VM Network?
Рекомендация для Isolation Responce
Причина
Не-VSAN машина (не хранится на хранилищах Virtual SAN)
Да
Да
Leave Powered On
ВМ работает нормально - зачем что-то делать?
Не-VSAN машина
Да
Нет
Leave Powered On
Подходит для большинства сценариев. Если же доступ машины к сети очень критичен и не критично состояние ее памяти - надо ставить Power Off, чтобы она рестартовала на других хостах (координация восстановления будет через сеть VSAN). Дефолтно же лучше оставить Leave Powered On.
VSAN и не-VSAN машина
Нет
Да
Leave Powered On
или
Power Off
См. таблицу ниже
VSAN и не-VSAN машина
Нет
Нет
Leave Powered On
или
Power Off
См. таблицу ниже
А теперь, собственно, таблица ниже, которая объясняет от чего зависят последние 2 пункта:
Наиболее вероятна ситуация, когда в случае изоляции хоста, все остальные также изолированы?
Будут ли хосты иметь доступ к heartbeat datastores,
если будут изолированы?
Важно ли сохранить память виртуальной машины при сбое?
Рекомендованная isolation policy (responce)
Причина
Нет
Да
Да
Leave Powered On
Важно состояние памяти ВМ. Так как есть доступ к хартбит-хранилищам, то ВМ не стартует на других хостах
Нет
Да
Нет
Power Off
Надо выключить ВМ, так как есть вероятность того, что ее вторая копия стартанет в другом сегменте разделенной сети.
Да
Нет
Да
Leave Powered On
Нет смысла выключать ВМ, так как хост-мастер операций не сможет инициировать ее восстановление, так как все хосты друг от друга изолированы.
Логика тут в принципе понятна, но в каждой конкретной ситуации может быть масса тонкостей касательно различных сценариев разделения и сбоев в сети, так что эти таблички лишь определяют направление мысли, а не дают готового рецепта.
Давно что-то не было новостей в сфере обновления инструментов для автоматизации операций в инфраструктуре VMware vSphere. Но вот они и пришли - сразу же после выхода VMware vSphere 5.5 и технологии Virtua SAN компания VMware выпустила обновление PowerCLI 5.5 R2.
Напомним, что PowerCLI является надстройкой над Microsoft PowerShell, которая позволяет администраторам просто управлять компонентами виртуальной инфраструктуры через командлеты:
Эта версия PowerCLI действительно принесла много нового, а именно:
Возможность создания/удаления тэгов и категорий тэгов.
Получение статуса и настройка режима Enhanced vMotion Compatibility (EVC) для кластеров.
Управление политиками безопасности для обычных виртуальных коммутаторов (vSwitch) и их групп портов.
Поддержка Windows PowerShell 4.0.
Поддержка серверов vSphere с настроенным IPv6.
Указание приоритета миграции ВМ (VMotionPriority для командлета Move-VM).
Возможность использования объекта Hard Disk как RelatedObject в методе Get-Datastore.
Командлет Get-Datastore позволяет фильтровать вывод по кластерам.
Командлеты Get-Stat и Get-StatType теперь работают со всеми типами, что позволяет собирать больше статистической информации.
Добавлена поддержка сетевых адаптеров e1000e.
Возможность указания всех значений в параметре DiskStorageFormat при клонировании виртуальной машины.
Поддержка 64-битных ОС для методов New-OSCustomizationSpec и Set-OSCustomizationSpec.
Свойство ToolsVersion объекта VMGuest показывает версию тулзов как строку.
Возможность использования объекта virtual portgroup как RelatedObject в методах Get-VirtualSwitch и Get-DVSwitch.
Получение списка ВМ рассортированного по виртуальным коммутаторам.
Различные исправления ошибок и улучшения производительности командлетов, которые можно посмотреть в логе изменений.
Вот какие штуки теперь можно использовать для решения VMware SRM через PowerCLI:
Protect a Virtual Machine - настройка репликации ВМ на удаленную площадку.
Connect-SrmServer - соединение с сервером vCenter Site Recovery Manager (SRM).
Create a Report of the Virtual Machines Associated with All Protection Groups - простенький отчет о виртуальных машинах и протекш-группах, в которые они входят.
Create a Report of the Protected Virtual Machines - простенький отчет о всех защищенных SRM виртуальных машинах.
Кроме vSphere PowerCLI 5.5 R2 обновился также и vCloud Director PowerCLI R2, который можно опционально установить при развертывании этого средства.
Мы довольно много пишем про кластеры хранилищ VMware Virtual SAN (VSAN), которые создаются на базе локальных дисков серверов VMware ESXi (например, тут и тут, а в последний раз - тут). А сегодня мы хотим рассказать о калькуляторе, который может пригодиться для расчета необходимой емкости хранилищ под Virtual SAN.
Написал его Duncan Epping, известный специалист по VMware vSphere и блоггер - один из немногих, которому можно верить.
Калькулятор рассчитывает общее количество требуемого дискового пространства (HDD и SSD-диски) как для кластера в целом, так и для одного хоста VMware ESXi, принимая в качестве исходных данных следующие параметры:
Количество ВМ в кластере хранилищ.
Объем оперативной памяти машины (vRAM).
Размер виртуального диска машины.
Число хостов, используемое для построения кластера.
Параметр Failures to tolerate (о нем мы писали тут).
Процент дискового пространства на метаданные и прочие издержки виртуализации хранилищ (по лучшим практикам - где-то 10%).
Процент пространства, которое занимает SSD-накопитель от дискового пространства на базе HDD-дисков хоста ESXi.
Поиграть с калькулятором дискового пространства для Virtual SAN можно по этой ссылке.
Как многие знают, в VMware vSphere 5.5 появились возможности Virtual SAN, которые позволяют создать кластер хранилищ для виртуальных машин на основе комбинации SSD+HDD локальных дисков серверов VMware ESXi. Не так давно вышла обновленная бета этого решения, кроме того мы не так давно писали о производительности VSAN тут и тут.
Сегодня же мы поговорим о том, как нужно сайзить хранилища Virtual SAN в VMware vSphere, а также немного затронем тему отказоустойчивости. Более детальную информацию можно найти в VMware Virtual SAN Design & Sizing Guide, а ниже мы расскажем о подходе к планированию хранилищ VSAN вкратце.
Объекты и компоненты Virtual SAN
Начнем с простого ограничения по объектам (objects) и компонентам (components), которое есть в VSAN. Виртуальные машины, развернутые на vsanDatastore, могут иметь 4 типа объектов:
Домашняя директория виртуальной машины Virtual Machine ("namespace directory").
Объект файла подкачки - swap object (для включенной ВМ).
Виртуальный диск VMDK.
Дельта-диски для снапшотов. Каждый дельта-диск - это отдельный объект.
Каждый объект, в зависимости от типа RAID, рождает некоторое количество компонентов. Например, один VMDK, размещенный на двух томах страйпа (RAID 0) рождает два объекта. Более подробно об этом написано вот тут.
Так вот, ограничения тут следующие:
Максимальное число компонентов на 1 хост ESXi: 3000.
Максимальное число компонентов для одного объекта: 64 (это включает в себя тома страйпов и также реплики VMDK с других хостов).
На практике эти ограничения вряд ли актуальны, однако о них следует знать.
Сколько дисков потребуется для Virtual SAN
Во второй бета-версии VSAN (и, скорее всего, так будет в релизной версии) поддерживается 1 SSD-диск и до 7 HDD-дисков в одной дисковой группе. Всего на один хост VMware ESXi поддерживается до 5 дисковых групп. Таким образом, на хосте поддерживается до 5 SSD-дисков и до 35 HDD-дисков. Надо убедиться, что контроллеры хоста поддерживают необходимое количество дисков, а кроме того нужно проверить список совместимости VSAN HCL, который постоянно пополняется.
Также надо учитывать, что кластер хранилищ Virtual SAN поддерживает расширение как путем добавления новых дисков, так и посредством добавления новых хостов в кластер. На данный момент VMware поддерживает кластер хранилищ максимум из 8 узлов, что суммарно дает емкость в дисках в количестве 40 SSD (1*5*8) и 280 HDD (7*5*8).
Сколько дисковой емкости нужно для Virtual SAN (HDD-диски)
Необходимая емкость под размещение VMDK зависит от используемого параметра FailuresToTolerate (по умолчанию 1), который означает, какое количество отказов хостов может пережить кластер хранилищ. Если установлено значение 1, то реплика одного VMDK будет размещена на дисках еще одного из хостов кластера:
Тут можно сказать о том, как работает отказоустойчивость кластера Virtual SAN. Если отказывает хост, на котором нет виртуальной машины, а есть только VMDK или реплика, то виртуальная машина продолжает работу с основной или резервной копией хранилища. В этом случае начнется процесс реконструкции реплики, но не сразу - а через 60 минут, чтобы дать время на перезагрузки хоста (то есть если произошел не отказ, а плановая или внеплановая перезагрузка), а также на короткие окна обслуживания.
А вот если ломается хост, где исполняется ВМ - начинается процедура восстановления машины средствами VMware HA, который перезапускает ее на другом хосте, взаимодействуя при этом с Virtual SAN.
Более подробно этот процесс рассмотрен вот в этой статье и вот в этом видео:
Однако вернемся к требующейся нам емкости хранилищ. Итак, если мы поняли, что значит политика FailuresToTolerate (FTT), то требуемый объем хранилища для кластера Virtual SAN равняется:
Capacity = VMDK Size * (FTT + 1)
Что, в принципе, и так было очевидно.
Сколько дисковой емкости нужно для Virtual SAN (SSD-диски)
Теперь перейдем к SSD-дискам в кластере VSAN, которые, как известно, используются для вспомогательных целей и не хранят в себе данных виртуальных машин. А именно, вот для чего они нужны (более подробно об этом тут):
Read Cache - безопасное кэширование операций на чтение. На SSD-диске хранятся наиболее часто используемые блоки, что уменьшает I/O read latency для ВМ.
Write Buffering - когда приложение внутри гостевой ОС пытается записать данные, оно получает подтверждение записи тогда, когда данные фактически записаны на SSD (не на HDD), таким образом твердотельный накопитель используется как буфер на запись, что небезопасно при внезапном пропадании питания или отказе хоста. Поэтому данные этого буфера дублируются на других хостах кластера и их SSD-дисках.
Так каковы же рекомендации VMware? Очень просты - под SSD кэш и буфер неплохо бы выделять 10% от емкости HDD-дисков хоста. Ну и не забываем про значение FailuresToTolerate (FTT), которое в соответствующее число раз увеличивает требования к емкости SSD.
Таким образом, необходимая емкость SSD-хранилищ равна:
Capacity = (VMDK Size * 0.1) * (FTT + 1)
Ну и напоследок рекомендуем отличнейший список статей на тему VMware Virtual SAN:
Поддержка обновленного ПО виртуализации как Microsoft, так и VMware была реализована Veeam очень вовремя, спустя небольшое время после выхода этих платформ.
Новые возможности Veeam Backup & Replication 7.0 R2:
VMware
Полная поддержка vSphere 5.5, включая поддержку виртуальных дисков 62 TB и Virtual hardware версии 10.
Поддержка средства управления облачной инфраструктурой vCloud Director 5.5.
Поддержка гостевых ОС Windows Server 2012 R2 и Windows 8.1 в виртуальных машинах.
Добавлена возможность ограничить число активных снапшотов на виртуальное хранилище, чтобы не допустить их переполнения. По умолчанию действует ограничение в 4 снапшота, и его можно изменить в реестре, в ключе MaxSnapshotsPerDatastore (REG_DWORD).
Microsoft
Поддержка платформы Windows Server 2012 R2 Hyper-V и бесплатного гипервизора Hyper-V Server 2012 R2, включая виртуальные машины второго поколения (Generation 2).
Поддержка гостевых ОС Windows Server 2012 R2 и Windows 8.1 в виртуальных машинах.
Поддержка System Center 2012 R2 Virtual Machine Manager (VMM).
Поддержка установки Veeam Backup & Replication и его компонентов на Windows Server 2012 R2 и Windows 8.1.
Built-in WAN acceleration
Улучшен механизм обработки данных - теперь он работает до 50% быстрее с использованием кэша жесткого диска, а производительность на SSD-накопителях улучшена до 3-х раз. Для этого рекомендуется использование многоядерных CPU на источнике с компонентом WAN accelerator.
Replication
Добавлена возможность для исходного и целевого прокси-серверов продолжить процесс репликации, когда сетевое соединение между ними пропало ненадолго.
Tape
Добавлена поддержка нескольких ленточных библиотек уровня предприятия с возможностью партишионинга - то есть предоставления нескольких разделов ленточной библиотеки одному хосту.
Возможность импорта/экспорта была доработана с целью поддержки некоторых библиотек IBM и Oracle/Sun.
Application-aware processing
Добавлена возможность обнаружения пассивной БД Microsoft Exchange DAG в виртуальной машине, что позволяет обработать эту машину корректно при резервном копировании.
Добавлена поддержка кластеров Exchange CCR.
User interface
Теперь запоминаются позиции и размеры окон графической консоли, а также размеры панелей и ширина колонок.
Это далеко не полный список возможностей нового B&R. Посмотреть их полностью и скачать Veeam Backup & Replication v7.0 R2 можно по этой ссылке.

 RSS
RSS